Spark Core 解析 3:Shuffle
Overview
所谓shuffle就是将数据按新的规则进行分区的过程,将数据分区从旧分区转变成新分区。
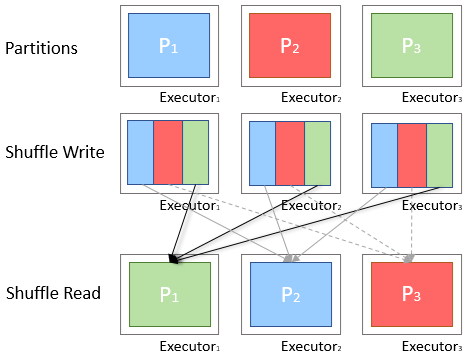
这个过程分为两个阶段,第一个阶段称为shuffle write,每个计算节点需要对自己持有的那部分数据按新分区规则进行重新分区,并按新分区写入文件。
shuffle write完成后,同一个新分区的数据会分散在不同的节点上,这样是不利于接下来的计算的,必须把同一个新分区的数据汇集到一个节点才行,所以需要第二阶段shuffle read。
shuffle read阶段将按照新分区,拉取shuffle write生成的文件,相同新分区的数据汇集到同一节点,组合成新的分区,这样才算是实现了新的数据分区。
Spark中负责实现shuffle的组件是ShuffleManger,其核心是ShuffleWriter和ShuffleReader两块,分别负责shuffle write和read的实现。
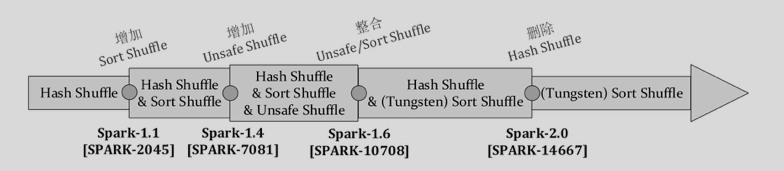
从下图可以看出,Spark的ShuffleManger经过不断的发展,到目前只剩下了一种即SortShuffleManager,本文的分析即是基于这种实现。
ShuffleWriter概述
顾名思义,ShuffleWriter就是Spark中负责shuffle write阶段的组件啦。
Spark2.x中虽然只有一种Shuffle管理器(SortShuffleManager),但是支持3种不同行为的ShuffleWriter,分别是SortShuffleWriter、BypassMergeSortShuffleWriter、UnsafeShuffleWriter。
下面先简单介绍下这几种ShuffleWriter,然后再做详细分析。
BypassMergeSortShuffleWriter
绕过排序和聚合的ShuffleWriter,这个是shuffle write最朴素的实现。
它将数据按新分区写到不同的文件,最后再把这些文件合并成一个文件,同时生成一个索引文件来标识数据块与分区的对应关系。
SortShuffleWriter
这是基于排序的ShuffleWriter,在BypassMergeSortShuffleWriter的基础之上,它可以支持对数据进行聚合,而且会对数据进行分区排序。
PS:为什么shuffle write阶段要对数据进行排序?
因为reduce操作通常会要对数据排序,如果在map端进行一次初排,可以减轻reduce的压力。
UnsafeShuffleWriter
可以使用堆外内存的ShuffleWriter,它的行为相当于不带聚合功能的SortShuffleWriter,但是可以使用堆外内存提高性能。
另一个优化点是,支持对序列化后的二进制数据排序,不仅能减少内存的消耗(因为序列化后的数据更紧凑),也能避免多次序列化反序列化(溢出到文件时需要序列化,合并文件时需要反序列化)的性能损耗。
会采用哪个ShuffleWriter
Spark自身会按如下规则对ShuffleWriter进行选择,从上往下依次判断:
- 1 当分区数(按新规则的)小于等于配置
spark.shuffle.sort.bypassMergeThreshold(默认为200)的值,使用BypassMergeSortShuffleWriter; - 2 如果当前依赖的serializer的序列化结果支持重排(后面解释),则使用UnsafeShuffleWriter;
- 3 否则采用SortShuffleWriter。
ShuffleReader概述
ShuffleReader只有一种即BlockStoreShuffleReader,顾名思义就是从BlockStore读取shuffle数据。
在进行shuffle read时,会异步拉取数据到内存或磁盘(大小超过一定阈值时)。拉取数据的同时对数据进行聚合(如果定义了聚合器)和排序(如果定义了排序器)操作。
到此为止,基本概念讲解完毕,下面开始讲原理。
Sorter 排序器
在shuffle过程中,有一个步骤不仅比较耗费资源,也是性能瓶颈之一,这个步骤就是排序,用来排序的组件称为Sorter。
要理解这3种ShuffleWriter的区别,必须先了解Sorter,因为他们的排序过程依赖不同的Sorter,导致他们的行为各异。
SortShuffleWriter使用的是ExternalSorter,
UnsafeShuffleWriter采用的是ShuffleExternalSorter,BypassMergeSortShuffleWriter则没有使用Sorter。
ExternalSorter 外部排序器
除了排序,这个排序器还支持数据的聚合和溢写到磁盘。它使用到了几个重要的数据结构,下面详细介绍下。
AppendOnlyMap (划重点)
AppendOnlyMap是一个支持新增和修改的哈希表,但是不支持删除元素。
底层存储结构很简单,就是一个数组Array[AnyRef],元素的key和value紧挨着存放,像这样:key0,value0,null,null,...,key1,value1,...。假如AppendOnlyMap的容量为capacity,那么这个数组的大小就是2 * capacity。
key到数组索引的映射也很简单,就是对key计算hash值,然后对容量取模,最后乘以2,hash(key) % capacity * 2。如果发生了哈希冲突,则继续探测后面的位置,第一次探测+2的位置,第二次探测+2+4的位置,以此类推,可以总结出一个公式 $idx+2*\sum_{i=1}^{k}i$ ,其中idx是根据hash值计算出的位置,k代表探测次数。
获取元素
如何取出元素呢,比如数据组名为data,key计算出索引为4,如果data(4)==key,那么对应的值就是data(5),如果data(4)!=key,那继续检查data(4+2)、data(4+2+4)等等是否等于key。
PS:支持key为null的元素,单独存储在一个变量中;
容量有个约束,它一定是2的幂。
插入元素
先根据上面的方法,计算出key对应的数据索引idx,如果idx上没有存储数据,那就直接在idx存下key,idx+1的位置存下value。如果idx上已经存了数,刚好就是要插入的key值,那也好办,直接更新value即可。
若idx上已经存了另一个key值,那就发生冲突了。接下来尝试idx+2的位置,如果继续冲突,则继续尝试idx+2+4、idx+2+4+6、…的位置,直到成功。
聚合元素
用来修改元素的API是changeValue(key: K, updateFunc: (Boolean, V) => V): V,处理流程基本与插入元素一样,只是当key已经存在时,会用updateFunc处理旧值与新值,如果传入的updateFunc是将新值与旧值merge的函数,那么就可以用changeValue方法来实现元素聚合的目的。
内置排序
进行排序的API是destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)],需要传入用来比较key的比较器,返回一个迭代器。
函数首先要对底层数组进行整理,将各元素向前移动,使得元素紧挨着排列,也就是把数组中空着的位置用后面的元素填上,然后使用TimSort排序算法(插入排序与归并排序结合的一种算法)对数组进行排序(使用传入的Comparator比较key),最后输出这个排序后数组的迭代器。
需要注意的是,经过排序后,AppendOnlyMap变成了destroyed状态,不再支持新增和修改元素,只能通过迭代器访问元素。
小结一下
AppendOnlyMap是一个类似map的数据结构,支持对相同元素进行聚合,同时也可以对元素进行排序,但是不支持删除元素。
PartitionedAppendOnlyMap
是AppendOnlyMap的子类,继承了AppendOnlyMap的功能,还另外实现了SizeTracker和WritablePartitionedPairCollection特质,主要是增加了集合大小估算(使用内存大小)、按分区和key排序、写入磁盘的功能。
PartitionedPairBuffer
底层是与AppendOnlyMap使用的一样的数组,但是元素不按哈希值存储,而是顺序存储(这样排序前就不需要整理数据了),同样支持排序,但是不支持对元素的聚合(因为采用的存储方式不支持随机存取元素)。
与PartitionedAppendOnlyMap类似,支持集合大小估算(使用内存大小)、按分区和key排序、写入磁盘的功能。
ExternalSorter 原理
ExternalSorter使用了PartitionedAppendOnlyMap和PartitionedPairBuffer作为数据buffer,或者说数据容器:
- 当需要进行map端聚合的时候,使用PartitionedAppendOnlyMap存储数据,这样就拥有了对数据进行聚合和分区排序功能;
- 当不需要进行map端聚合的时候,使用PartitionedPairBuffer,就获得了性能更好(因为不需要整理数据)的分区排序功能。
总的来说,ExternalSorter的功能有:缓冲数据、分区排序、输出排序后的数据到文件。
溢写
另外,ExternalSorter实现了将数据溢出到磁盘的功能,这样即使内存无法装下所有的数据,也能进行分区排序。溢写到磁盘的数据,最终会与内存中的数据合并后再持久化到磁盘。
所谓溢写,是指内存装不下不断增加的数据了,只好把内存中的数据写到磁盘的过程。
ExternalSorter的溢写过程大致是:
- 1 当buffer内存使用量大于阈值,并且申请不到更多内存的时候,启动溢写;
- 2 调用buffer的排序函数,并将数据写入磁盘;
- 3 创建一个新的buffer,继续接受新数据。
输出最终结果的时候,会把所有的溢写文件,连同内存中的数据,通过归并排序(merge sort)合并成一个文件。
ShuffleExternalSorter
这也是一种外部排序器,支持分区排序和数据溢出到磁盘,但是不支持数据聚合,也不支持合并溢写文件。溢写文件合并的工作由UnsafeShuffleWriter完成。
比较特别的是,这个排序器可以使用堆外(off-heap)内存,因为使用了Unsafe类操作内存。Unsafe类不仅能操作off-heap内存,也能操作on-heap内存,所以ShuffleExternalSorter是既能使用堆内内存,也能使用堆外内存的。
ShuffleReader
ShuffleReader只有一种即BlockStoreShuffleReader。
在进行shuffle read时,会先创建ShuffleBlockFetcherIterator,通过ShuffleClient开始异步拉取数据到内存或磁盘(大小超过一定阈值时)。拉取数据的同时对数据进行聚合(如果定义了聚合器)和排序(如果定义了排序器)操作。其中聚合操作使用的是ExternalAppendOnlyMap,排序则是使用ExternalSorter。
经典的SortShuffle过程
简化版本
shuffle write阶段:
- 1 SortShuffleWriter不断从RDD的迭代器取出数据并存入buffer。如果有定义聚合操作,会采用PartitionedAppendOnlyMap作为buffer,边插入边聚合数据,否则使用PartitionedPairBuffer,只插入数据不做聚合。存入buffer过程中,如果内存不够,会触发spill,将数据排序后溢写到磁盘;
- 2 对buffer中的数据按新分区和key进行排序,如果有spill文件,则进行合并,然后输出一个数据文件(data file)和一个索引文件(index file),返回MapStatus。
shuffle read阶段:
- 1 BlockStoreShuffleReader先通过mapOutputTracker获取需要拉取的block信息,然后开始拉取数据到buffer中;
- 2 拉取数据的同时,如果该ShuffleDependency有定义聚合器,则会通过ExternalAppendOnlyMap对数据进行聚合;接下来,如果该ShuffleDependency有定义排序器,则会使用ExternalSorter进行排序,最终会返回一个迭代器。
详细版本
假若使用的是SortShuffleWriter和BlockStoreShuffleReader,接下来对照2.4版本的源码,做个整体流程分析。
这一切从ShuffleMapTask开始… (不知道什么是ShuffleMapTask,请看Spark Core解析 2:Scheduler 调度体系)
- 1 ShuffleMapTask的runTask方法被Executor的某个线程执行,task开始执行;
- 2 runTask方法调用SortShuffleManager.getWriter方法,创建SortShuffleWriter实例,然后调用SortShuffleWriter.write方法,开启shuffle write阶段;
- 3 write方法中会new一个ExternalSorter实例,并调用这个实例的insertAll方法,并传入RDD(所属stage最后一个RDD)对应的一个分区的Iterator,进入数据缓冲聚合阶段;
- 4 insertAll方法中,每从Iterator中取一个值,就把这个值存入内存中的缓冲数据结构buffer。从Iterator中取值会触发RDD上用户定义的计算逻辑,取出的这一条数据其实是从数据源读出并经过各种父RDD的计算逻辑后得到的结果。如果有定义聚合操作,会采用PartitionedAppendOnlyMap作为buffer,边插入边聚合数据,否则使用PartitionedPairBuffer,只插入数据不做聚合。存入buffer过程中,如果内存不够,会触发spill,将数据排序后溢写到磁盘,然后创建新的buffer,继续存入数据;
- 5 数据全部存入buffer后,开始排序输出阶段。SortShuffleWriter.write方法调用ExternalSorter.writePartitionedFile方法,对buffer中的数据按新分区和key进行排序(如果有spill文件,则利用heap结构进行merge sort),然后输出一个数据文件(data file)和一个索引文件(index file),索引文件中记录了数据文件中每个分区的数据开始的offset。(注意:buffer的输入数据虽然只有一个分区,但是输出会按新分区方式输出多个分区的数据。)
- 6 write方法写完数据后,返回MapStatus(包含shuffleServerId和分区信息),最终MapStatus会发送给DAGScheduler,然后被MapOutputTracker记录任务信息,
- 7 shuffle write结束,下面说说shuffle read。
shuffle read既可能发生在ShuffleMapTask也可能发生在ResultTask,这取决于task所属stage包含的RDD的dependency
是否含有ShuffleDependency,对于ShuffleDependency,RDD的compute函数会调用BlockStoreShuffleReader.read方法,开启read流程。 - 8 read函数中会先通过mapOutputTracker获取需要拉取的block信息,然后创建ShuffleBlockFetcherIterator,ShuffleBlockFetcherIterator被创建后会立即开始拉取数据(通过ShuffleClient),拉取过程是异步的,拉取到的数据会暂存到buffer中。
- 9 拉取数据的同时,如果该ShuffleDependency有定义聚合器,则会通过ExternalAppendOnlyMap对数据进行聚合;接下来,如果该ShuffleDependency有定义排序器,则会使用ExternalSorter进行排序。
- 10 read函数最终会返回一个Iterator,成为task的数据来源。
小结:如果有n个ShuffleMapTask,write阶段最终会生成2n个临时文件(不含spill文件),read阶段除了spill文件不会产生临时数据文件。
黑科技UnsafeShuffle过程
UnsafeShuffleWriter.write方法,间接调用ShuffleExternalSorter.insertRecord方法,传入序列化后的数据record,数据缓冲过程开始;
- 缓冲阶段第1步,根据情况进行溢写。
ShuffleExternalSorter.insertRecord方法中,先检查记录数,达到阈值,则进行spill溢写;溢写过程大致为:调用ShuffleInMemorySorter.getSortedIterator对存入的recordAddress地址排序,这里只是按partitionId排序(RadixSort和TimSort两种算法),按照排序好的recordAddress,依次输出数据(仍然是序列化后的)到一个文件,并记录每个partition的offset到SpillInfo中; - 缓冲阶段第2步,申请内存块page。
如果ShuffleExternalSorter的currentPage空间不足,会先申请page(即MemoryBlock);申请过程会依次使用到TaskMemoryManager.allocatePage和MemoryManager.tungstenMemoryAllocator().allocate,依据MemoryManager使用的MemoryAllocator是HeapMemoryAllocator还是UnsafeMemoryAllocator,申请到的MemoryBlock是on-heap和off-heap类型地址的其中一种; - 缓冲阶段第3步,数据写入page。
currentPage空间足够后,依次将record字节大小,record本身复制到currentPage中以pageCursor开始的地址段中,并增加pageCursor游标地址; - 缓冲阶段第4步,保存record地址。
通过taskMemoryManager.encodePageNumberAndOffset得到recordAddress,连同partitionId存入ShuffleInMemorySorter;
当数据全部缓冲完毕,开始排序输出阶段。
- 接下来write方法会间接调用ShuffleExternalSorter.writeSortedFile,将内存中剩下的数据全部溢写;
- UnsafeShuffleWriter.mergeSpills方法将spill的文件全部合并成一个,这里会利用之前保存的SpillInfo,将相同partition的数据合到一起;(这里合并有三种实现:transferTo-based fast merge,fileStream-based fast merge,slow merge)
- 通过shuffleBlockResolver.writeIndexFileAndCommit创建索引文件;
- 返回mapStatus;
- shuffle write阶段结束,read阶段与SortShuffle相同
小结:
如果配置了spark.memory.offHeap.enabled和spark.memory.offHeap.size参数,则会使用off-heap缓冲数据;
数据和地址指针分开存储,排序只是对地址指针进行。
UnsafeShuffleWriter的黑科技主要体现在:
- write全程只在第一步做了数据序列化,后面操作的都是序列化后的数据,甚至写文件时也没有再进行序列化;
- 使用off-heap内存存储数据,大大减少JVM GC压力,而且避免了IO时数据在堆内堆外内存之间的拷贝;
- 使用地址指针进行排序,减少了序列化反序列化的性能消耗;
- spill文件合并时,‘transferTo-based fast merge’使用NIO提供的transferTo方法,文件数据直接在内核空间(kernel-space)拷贝合并,提升了性能。
参考文献
Spark内核设计的艺术
转载请注明原文地址:Liam’s Blog