Spark Core解析 2:Scheduler 调度体系
Overview
调度系统,是贯穿整个Spark应用的主心骨,从调度系统开始入手了解Spark Core,比较容易理清头绪。
Spark的资源调度采用的是常见的两层调度,底层资源的管理和分配是第一层调度,交给YARN、Mesos或者Spark的Standalone集群处理,Application从第一层调度拿到资源后,还要进行内部的任务和资源调度,将任务和资源进行匹配,这是第二层调度,本文讲的就是这第二层调度。
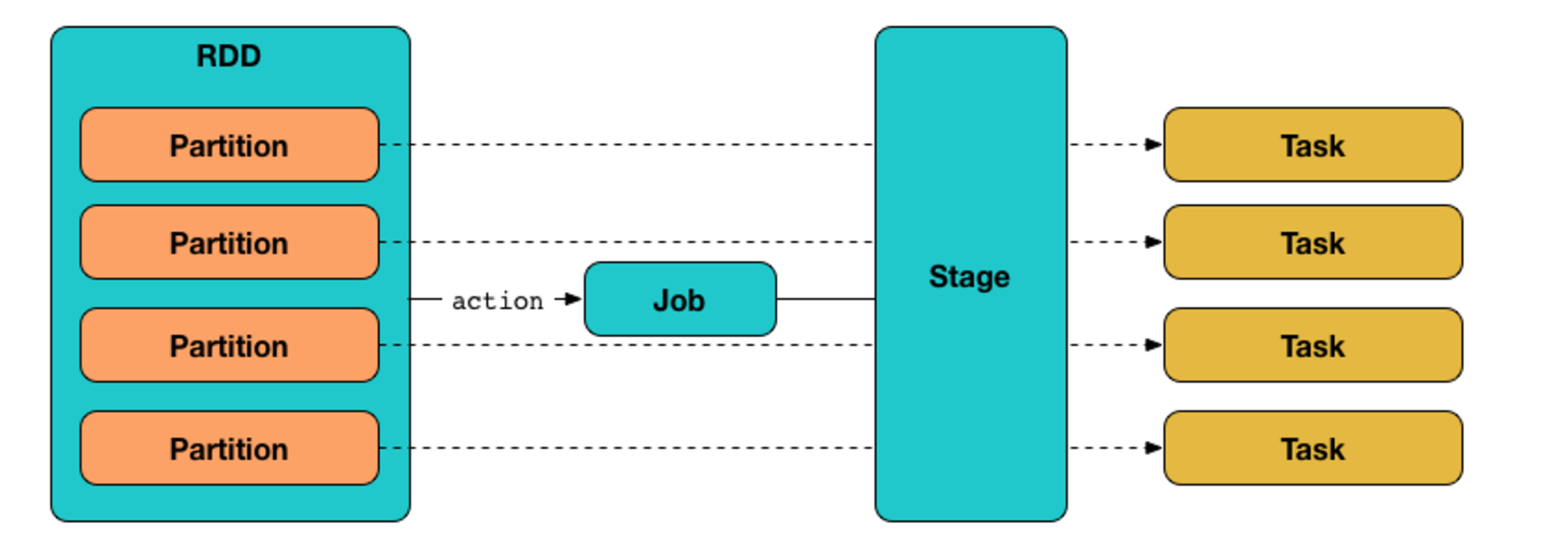
Spark的调度体系涉及的任务包括3个粒度,分别是Job、Stage、Task。
Job代表用户提交的一系列操作的总体,一个具体的计算任务,有明确的输入输出,一个Job由多个Stage组成;
一个Stage代表Job计算流程的一个组成部分,一个阶段,包含多个Task;
一个Task代表对一个分区的数据进行计算的具体任务。
层级关系:Job > Stage > Task
在Spark Core 解析:RDD 弹性分布式数据集中,已经解释了RDD之间的依赖,以及如何组成RDD血缘图。
所以本文主要目的就是解释清楚:Scheduler将RDD血缘图转变成Stage DAG,然后生成Task,最后提交给Executor去执行的过程。
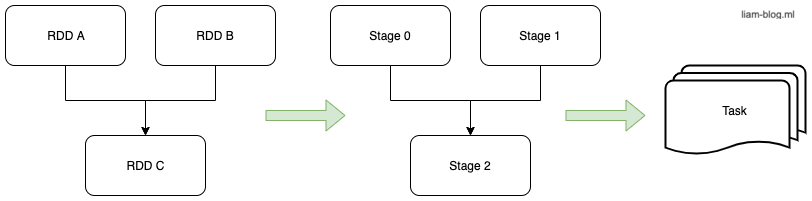
Stage
Job的不同分区的计算通常可以并行,但是有些计算需要将数据进行重新分区,这个过程称作shuffle(混洗)。Shuffle的过程是没法完全并行的,这时候就会出现task之间的等待,task的数量也可能发生变化,所以Spark中以shuffle为边界,对task进行划分,划分出来的每段称为Stage。
Stage代表一组可以并行的执行相同计算的task,每个任务必须有相同的分区规则,这样一个stage中是没有shuffle的。
在一个Spark App中,stage有一个全局唯一ID,stage id是自增的。
Stage分为两种:
- ResultStage:最后执行的stage,负责Job最终的结果输出,每个Job有且仅有一个ResultStage;
- ShuffleMapStage:该stage的输出不是最终结果,而是其他stage的输入数据,通常涉及一次shuffle计算。
stage创建流程:
- 从最终执行action的RDD开始,沿着RDD依赖关系遍历,
一旦发现某个RDD的dependency是ShuffleDependency,就创建一个ShuffleMapStage。 - 最后创建ResultStage。
example 1
1 | val rg=sc.parallelize(List((1,10),(2,20))) |
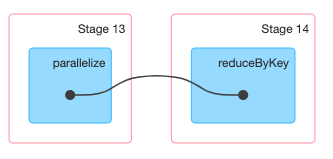
这里reduceByKey操作引起了一次shuffle,所以job被切分成了2个stage。
example 2
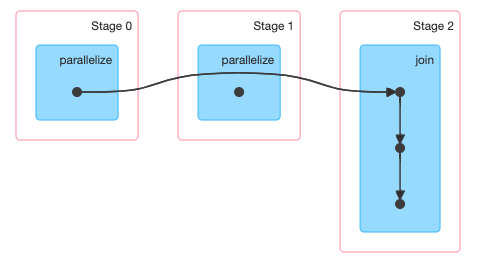
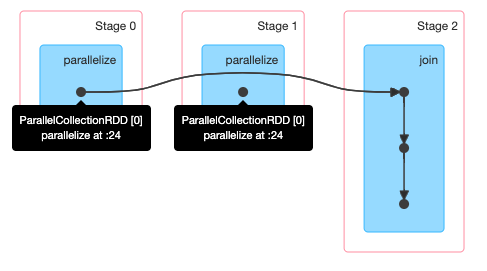
1 | val rddA=sc.parallelize(List((1,"a"),(2,"b"),(3,"c"))) |
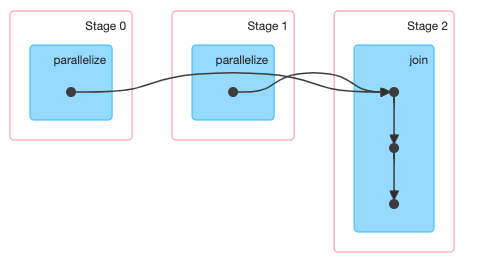
join操作导致rddA和rddB都进行了一次shuffle,所以有3个stage。
example 3
1 | import org.apache.spark.HashPartitioner |
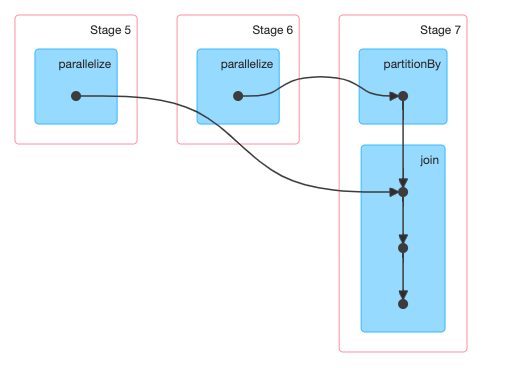
WHAT ?
因为rddA已经定义了Partitioner,这里join操作会保留rddA的分区方式,所以对rddA的依赖是OneToOneDepenency,而对于rddB则是ShuffleDependency。
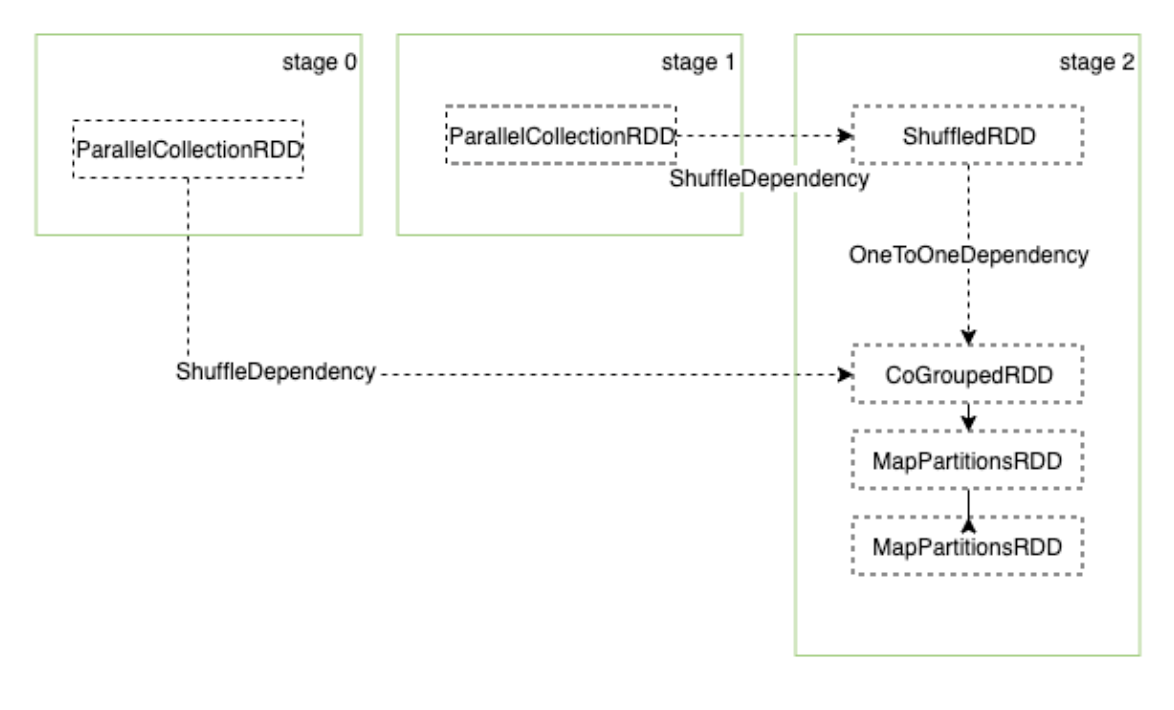
探索:一个RDD被依赖多次,会如何
1 | val rddA=sc.parallelize(List((1,"a"),(2,"b"),(3,"c"))) |
一个RDD被两个stage使用了。
小结
综上,stage的划分一定是依据shuffle即ShuffleDependency,跟算子和RDD变量的定义没有很强的关系,example2和3中的join操作rddA.join(rddB).collect看起来一模一样,但实际产生的stage划分却差别很大。
Task
与stage对应,task也分为两种:
- ShuffleMapTask:即ShuffleMapStage中的task,主要完成map、shuffle计算。
- ResultTask:ResultStage中的task,主要完成最终结果输出或者返回结果给driver的任务。
一个stage有多少个partition就会创建多少个task,比如一个ShuffleMapStage有10个partition,那么就会创建10个ShuffleMapTask。
一个Stage中的所有task组成一个TaskSet。
Job Submit
1 | graph TB |
RDD在action操作中通过SparkContext.runJob方法触发Job执行流程,该方法将调用DagScheduler.runJob方法,将RDD传入DagScheduler。然后,DAGScheduler创建TaskSet提交给TaskScheduler,TaskScheduler再将TaskSet封装成TaskDescription发送给Executor,最后Executor会将TaskDescription提交给线程池来运行。
Stage Scheduler(high-level)
DagScheduler
Stage级别的调度是DagScheduler负责的,也是Spark调度体系的核心。
DagScheduler的工作模式
1 | sequenceDiagram |
DagScheduler内部维护了一个事件消息总线eventProcessLoop(类型为DAGSchedulerEventProcessLoop),其实就是一个用来存储DAGSchedulerEvent类型数据的队列。
当DagScheduler的一些方法被调用的时候(如submitJob方法),并不会在主线程中处理该任务,而是post一个event(如JobSubmitted)到eventProcessLoop。eventProcessLoop中有一个守护线程,会不断的依次从队列中取出event,然后调用对应的handle(如handleJobSubmitted)方法来执行具体的任务。
Stage调度流程
1.submit job
DagScheduler.runJob方法会调用submitJob方法,向eventProcessLoop发送一个JobSubmitted类型的消息,其中包含了RDD等信息。当eventProcessLoop接收到JobSubmitted类型的消息,会调用DagScheduler.handleJobSubmitted方法来处理消息。
1 | sequenceDiagram |
2.create stage
DagScheduler在它的handleJobSubmitted方法中开始创建ResultStage。ResultStage中包含了最终执行action的finalRDD,以及计算函数func。
ResultStage有个parents属性,这个属性是个列表,也就是说可以有多个parent stage。创建ResultStage时需要先创建它的parent stage来填充这个属性,也就是说要创建ResultStage直接依赖的所有ShuffleMapStage。
通过stage.rdd.dependencies属性,采用宽度优先遍历,一旦发现某个RDD(假设叫rddA)的dependency是ShuffleDependency,就创建一个ShuffleMapStage,ShuffleMapStage中包含的关键信息与ResultStage不同,是rddA的ShuffleDependency和rddA的ShuffleDependency.rdd,也就是说新创建的ShuffleMapStage持有的信息是他自身的最后一个RDD和该RDD的子RDD的dependency。
创建一个ShuffleMapStage的过程同理会需要创建它的parent stage,也是若干ShuffleMapStage。如此递归下去,直到创建完所有的ShuffleMapStage,最后才完成ResultStage的创建。最后创建出来的这些Stage(若干ShuffleMapStage加一个ResultStage),通过parent属性串起来,就像这样
1
2
3
4graph TD
A[ResultStage]-- parent -->B[ShuffleMapStage 1]
A-- parent -->C[ShuffleMapStage 2]
B-- parent -->D[ShuffleMapStage 3]这就生成了所谓的DAG图,但是这个图的指向跟执行顺序是反过来的,如果按执行顺序来画DAG图,就是常见的形式了:
1
2
3
4graph TD
D[ShuffleMapStage 3]-->C[ShuffleMapStage 2]
C[ShuffleMapStage 2]-->A[ResultStage]
B[ShuffleMapStage 1]-->A[ResultStage]
3.submit stage
DagScheduler.handleJobSubmitted方法创建好ResultStage后会提交这个stage(submitStage方法),在提交一个stage的时候,会要先提交它的parent stage,也是通过递归的形式,直到一个stage的所有parent stage都被提交了,它自己才能被提交,如果一个stage的parent还没有完成,则会把这个stage加入waitingStages。也就是说,DAG图中前面的stage会被先提交。当一个stage的parent都准备好了,也就是执行完了,它才会进入submitMissingTasks的环节。
4.submit task
Task是在DagScheduler(不是TaskScheduler)的submitMissingTasks方法中创建的,包括ShuffleMapTask和ResultTask,与Stage对应。归属于同一个stage的这批Task组成一个TaskSet集合,最后提交给TaskScheduler的就是这个TaskSet集合。
Task Scheduler(low-level)
Task的调度工作是由TaskScheduler与SchedulerBackend紧密合作,共同完成的。
TaskScheduler是task级别的调度器,主要作用是管理task的调度和提交,是Spark底层的调度器。
SchedulerBackend是TaskScheduler的后端服务,有独立的线程,所有的Executor都会注册到SchedulerBackend,主要作用是进行资源分配、将task分配给executor等。
Task调度流程
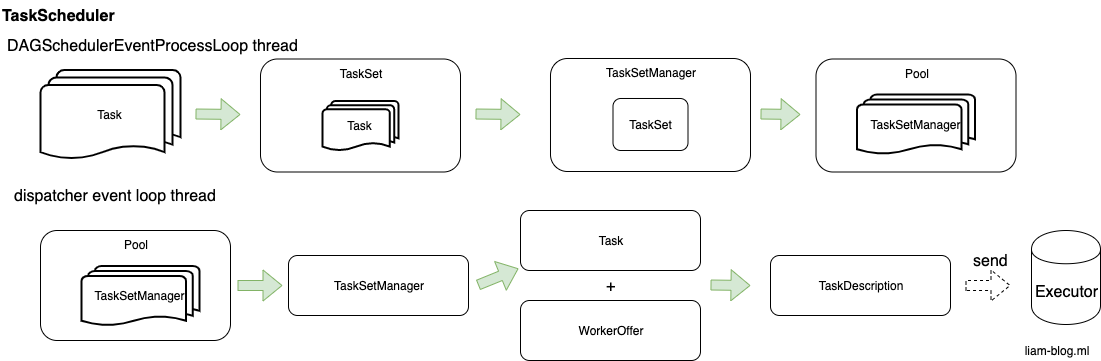
第一个线程是DAGScheduler的事件处理线程,在其中,Task先经过DAGScheduler(蓝色箭头表示)封装成TaskSet,再由TaskScheduler(绿色箭头)封装成TaskSetManager,并加入调度队列中。
SchedulerBackend在收到ReviveOffers消息时,会从线程池取一个线程进行makeOffers操作,WorkerOffer创建后传递给TaskScheduler进行分配。
图中第二个线程就是SchedulerBackend的一个事件分发线程,从Pool中取出最优先的TaskSetManager,然后将WorkerOffer与其中的Task进行配对,生成TaskDescription,发送给WorkerOffer指定的Executor去执行。
工作流程
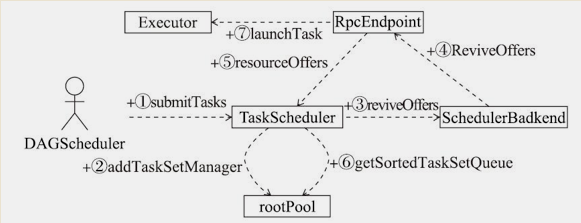
- 1 DAGScheduler(submitMissingTasks方法中)调用TaskScheduler.submitTasks()创建并提交TaskSet给TaskScheduler;
- 2 TaskScheduler拿到TaskSet后会创建一个TaskSetManager来管理它,并且把TaskSetManager添加到rootPool调度池中;
- 3 调用SchedulerBackend.reviveOffers()方法;
- 4 SchedulerBackend发送ReviveOffers消息给DriverEndpoint;
- 5 DriverEndpoint收到ReviveOffers消息后,会调用makeOffers()方法创建WorkerOffer,并通过TaskScheduler.resourceOffers()返回offer;
- 6 TaskScheduler从rootPool获取按调度算法排序后的TaskSetManager列表,取第一个TaskSetManager,逐个给TaskSet的Task分配WorkerOffer,生成TaskDescription(包含offer信息);
- 7 调用SchedulerBackend.DriverEndpoint的launchTasks方法,将TaskDescription序列化并封装在LaunchTask消息中,发送给offer指定的executor。LaunchTask消息被ExecutorBackend收到后,会将Task信息反序列化,传给Executor.launchTask(),最后使用Executor的线程池中的线程来执行这个Task。
梳理
Stage,TaskSet,TaskSetManager是一一对应的,数量相等,都是只存在driver上的。
Parition,Task,TaskDescription是一一对应,数量相同,Task和TaskDescription是会被发到executor上的。
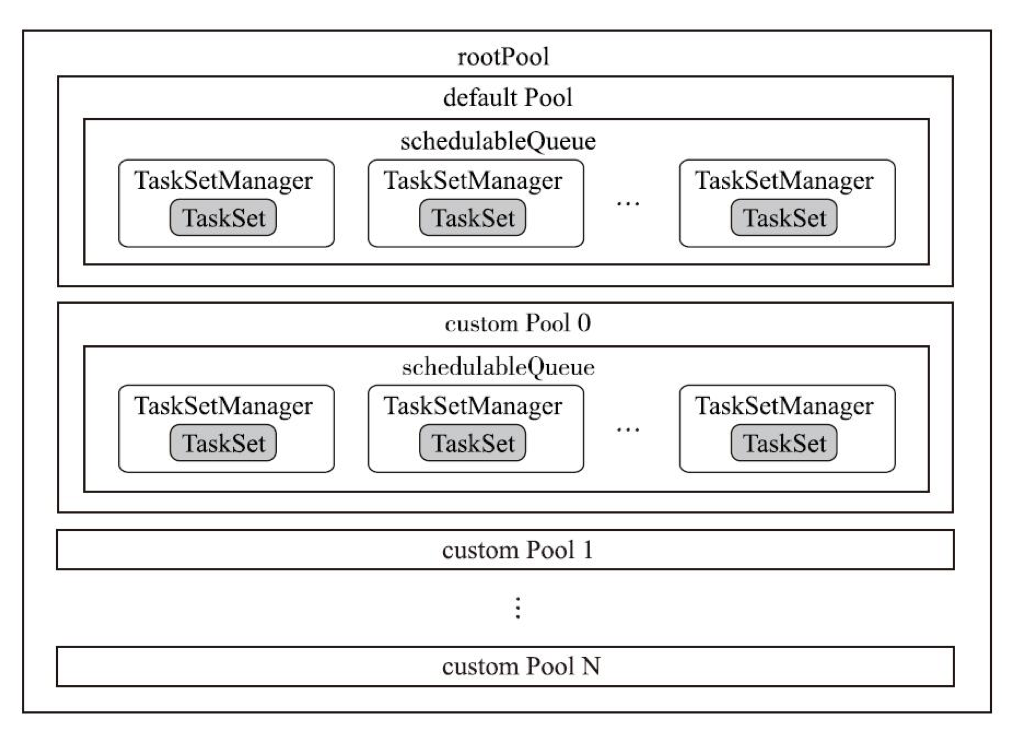
TaskScheduler的调度池
与DAGScheduler不同的是TaskScheduler有调度池,有两种调度实体,Pool和TaskSetManager。
与YARN的调度队列类似,采用了层级队列的方式,Pool是TaskSetManager的容器,起到将TaskSetManager分组的作用。
Schedulable
Schedulable是调度实体的基类,有两个子类Pool和TaskSetManager。
要理解调度规则,必须知道下面几个属性:
- parent:所属调度池,顶层的调度池为root pool;
- schedulableQueue:包含的调度对象组成的队列;
- schedulingMode:调度模式,FIFO or FAIR;
- weight:权重
- minShare:最小分配额(CPU核数)
- runningTasks:运行中task数
- priority:优先级
- stageId:就是stageId
- name:名称
Pool和TaskSetManager对于这些属性的取值有所不同,从而导致了他们的调度行为也不一样。
| properties | Pool | TaskSetManager |
|---|---|---|
| weight | config | 1 |
| minShare | config | 0 |
| priority | 0 | jobId |
| stageId | -1 | stageId |
| name | config | TaskSet_{taskSet.id} |
| runningTasks | Pool所含TaskSetManager的runningTasks和 | TaskSetManager运行中task数 |
Pools创建流程
TaskScheduler有个属性schedulingMode,值取决于配置项spark.scheduler.mode,默认为FIFO。这个属性会导致TaskScheduler使用不同的SchedulableBuilder,即FIFOSchedulableBuilder和FairSchedulableBuilder。
TaskScheduler在初始化的时候,就会创建root pool,根调度池,是所有pool的祖先。
它的属性取值为:
1 | name: "" (空字符串) |
注意root pool的调度模式确定了。
接下来会执行schedulableBuilder.buildPools()方法,
如果是FIFOSchedulableBuilder,则什么都不会发生。
若是FairSchedulableBuilder
- 1 依据scheduler配置文件(后面会说),开始创建pool(可以是多个pool,FIFO,FAIR都有可能,取决于配置文件),并都加入root pool中。
- 2 如果现在root pool中没有名为”default”的pool(即配置文件中没有定义一个叫default的pool),创建default pool,并加入root pool中。
这时default pool它的属性取值是固定的:
1
2
3
4name: "default"
schedulingMode: FIFO
weight: 1
minShare: 0
Task加入pool流程
当TaskScheduler提交task的时候,会先创建TaskSetManager,然后通过schedulableBuilder添加到pool中。
如果是FIFOSchedulableBuilder,则会直接把TaskSetManager加入root pool队列中。
若是FairSchedulableBuilder
- 1 从
spark.scheduler.pool配置获取pool name,没有定义则用’default’; - 2 从root pool遍历找到对应名称的pool,把TaskSetManager加入pool的队列。如果没有找到,则创建一个该名称的pool,采用与default pool相同的属性配置,并加入root pool。
- 1 从
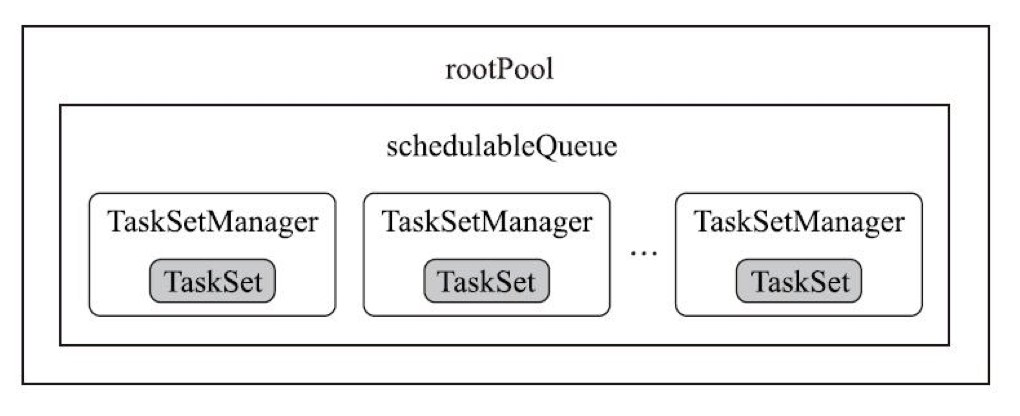
调度池结构
经过上面两部分,最终得到的调度池结构如下:
spark.scheduler.mode=FIFO
spark.scheduler.mode=FAIR
Fair Scheduler pools配置
Fair Scheduler Pool的划分依赖于配置文件,默认的配置文件为’fairscheduler.xml’,也可以通过配置项”spark.scheduler.allocation.file”指定配置文件。
煮个栗子,文件内容如下:
1 |
|
这里配置了两个pool,prod和test,并且配置了相关属性,这两个pool都会添加到root pool中。
调度算法
以SchedulingAlgorithm为基类,内置实现的调度算法有两种FIFOSchedulingAlgorithm和FairSchedulingAlgorithm,其逻辑如下:
FIFO: 先进先出,优先级比较算法如下,
- 1.比较priority,小的优先;
- 2.priority相同则比较StageId,小的优先。
FAIR:公平调度,优先级比较算法如下,
- 1.runningTasks小于minShare的优先级比不小于的优先级要高。
- 2.若两者运行的runningTasks都比minShare小,则比较minShare使用率(runningTasks/max(minShare,1)),使用率越低优先级越高。
- 3.若两者的minShare使用率相同,则比较权重使用率(runningTasks/weight),使用率越低优先级越高。
- 4.若权重也相同,则比较name,小的优先。
Pool为FIFO模式下的几种情形
TaskSetManager之间的比较,其实就是先比较jobId再比较stageId,谁小谁优先,意味着就是谁先提交谁优先。
Pool之间的比较,不存在!FIFO的pool队列中是不会有pool的。
Pool为FAIR模式下的几种情形
TaskSetManager之间的比较,因为minShare=0,weight=1,FAIR算法变成了:
- 1 runningTasks小的优先
- 2 runningTasks相同则比较name
Pool之间的比较,就是标准的FAIR算法。
当root pool为FAIR模式,先取最优先的pool,再从pool中,按pool的调度模式取优先的TaskSetManager。
开始使用FAIR mode
启用FAIR模式:
- 1 准备好
fairscheduler.xml文件 - 2 启动参数添加
--conf spark.scheduler.mode=FAIR - 3 运行启动命令,如
spark-shell --master yarn --deploy-mode client --conf spark.scheode=FAIR
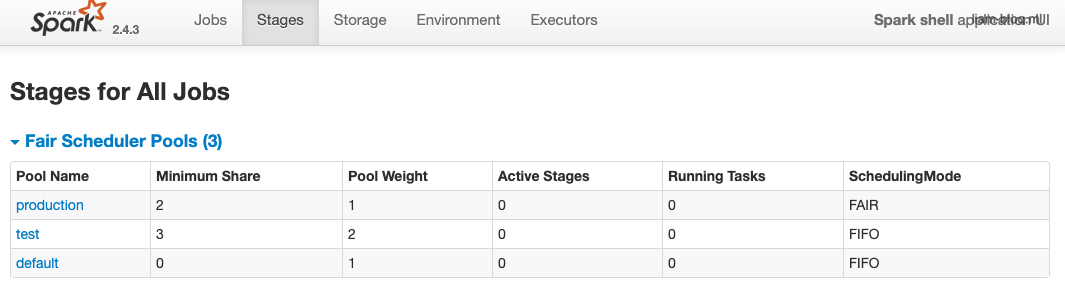
启动后如果直接运行Job会自动提交到default pool,那么如何提交Job到指定pool?
SparkContext.setLocalProperty(“spark.scheduler.pool”,”poolName”)
如果每次只运行一个Job,开启FAIR模式的意义不大,那么如何同时运行多个Job?
要异步提交Job,需要用到RDD的async action,目前有如下几个:
1 | countAsync |
举个例子:
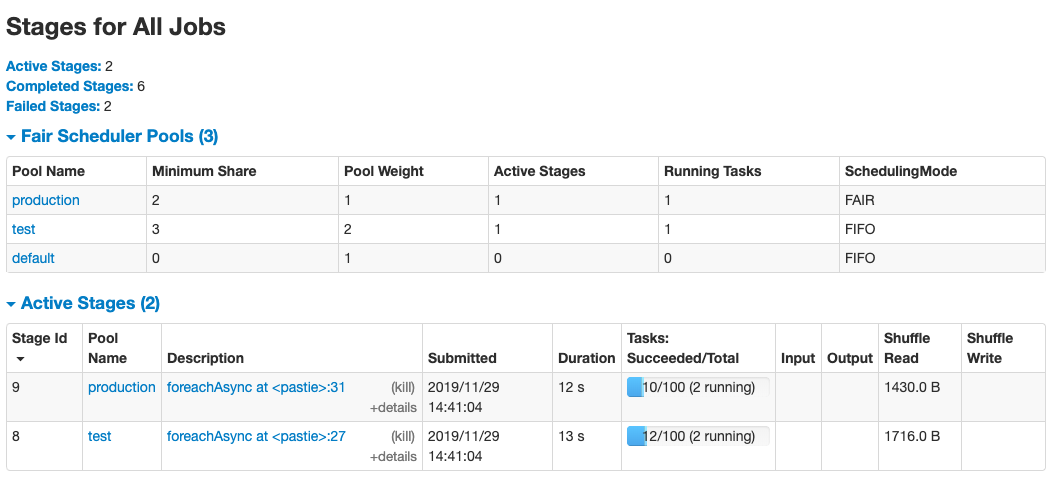
1 | sc.setLocalProperty("spark.scheduler.pool","test") |
这样就会有两个任务在不同的pool同时运行:
FAIR mode应用场景
场景1:Spark SQL thrift server
作用:让离线任务和交互式查询任务分配到不同的pool,给交互式查询任务更高的优先级,这样长时间运行的离线任务就不会一直占用所有资源,阻塞交互式查询任务。
场景2:Streaming job与Batch job同时运行
作用:比如用Streaming接数据写入HDFS,可能产生很多小文件,可以在低优先级的pool定时运行batch job合并小文件。
另外可以参考Spark Summit 2017的分享:Continuous Application with FAIR Scheduler
参考
转载请注明原文地址:
https://liam-blog.ml/2019/11/07/spark-core-scheduler/