Spark Core解析 1:RDD 弹性分布式数据集
引言
Spark Core是Spark的核心部分,是Spark SQL,Spark Streaming,Spark MLlib等等其他模块的基础, Spark Core提供了开发分布式应用的脚手架,使得其他模块或应用的开发者不必关心复杂的分布式计算如何实现,只需使用Spark Core提供的分布式数据结构RDD及丰富的算子API,以类似开发单机应用的方式来进行开发。
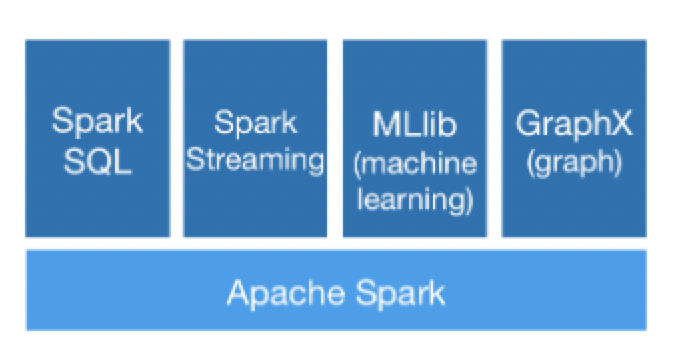
图中最下面那个就是Spark Core啦,日常使用的RDD相关的API就属于Spark Core,而Dataset、DataFrame则属于Spark SQL。
RDD 概览
本文基于Spark 2.x。
定义
RDD (Resilient Distributed Dataset,弹性分布式数据集):
- Resilient:不可变的、容错的
- Distributed:数据分散在不同节点(机器,进程)
- Dataset:一个由多个分区组成的数据集
特征
In-Memory:RDD会优先使用内存
Immutable(Read-Only):一旦创建不可修改
Lazy evaluated:惰性执行
Cacheable:可缓存,可复用
Parallel:可并行处理
Typed:强类型,单一类型数据
Partitioned:分区的
Location-Stickiness:可指定分区优先使用的节点
是Spark中最核心的数据抽象,数据处理和计算基本都是基于RDD。
组成
一个RDD通常由5个要素组成:
- 一组分区(partition)
- 一个计算函数
- 一组依赖(直接依赖的父RDD)
- 一个分区器 (可选)
- 一组优先计算位置(e.g. 将Task分配至靠近HDFS块的节点进行计算) (可选)
与传统数据结构对比,只关心访问,不关心存储。通过迭代器访问数据,只要数据能被不重复地访问即可。
算子
算子,即对RDD进行变换的操作,按照是否触发Job提交可以分为两大类:
- transformation:不会立即执行的一类变换,不会触发Job执行,会生成并返回新的RDD,同时记录下依赖关系。如:map,filter,union,join,reduceByKey。
- action: 会立即提交Job的一类变换,不会返回新的RDD,而是直接返回计算结果。如:count,reduce,foreach。
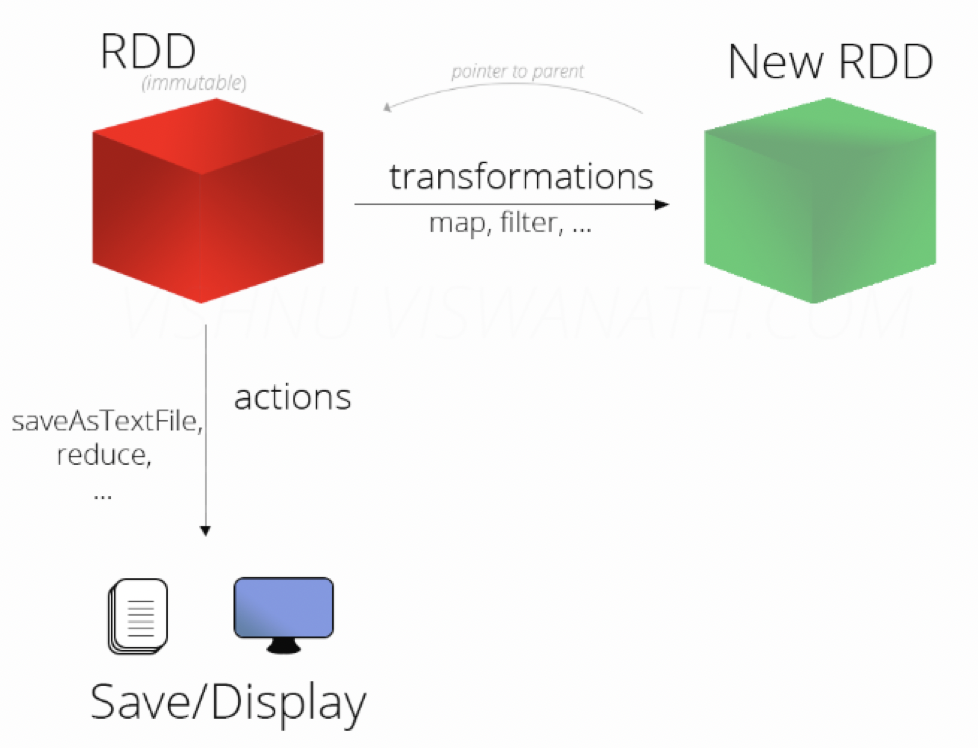
算子与RDD的关系
transformation类型的算子通常都会返回新的RDD,虽然只返回一个新的RDD给用户,但是在RDD的血缘关系图(RDD linage)中,有可能新增了多个RDD。
先看算子与RDD一对一的情况:
map => MapPartitionsRDD
filter => MapPartitionsRDD
reduceByKey => ShuffledRDD
…

一对多:
join => CoGroupedRDD->MapPartitionsRDD->MapPartitionsRDD
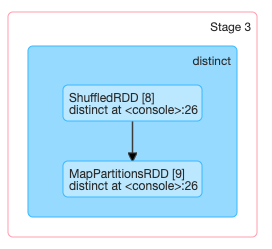
distinct => MapPartitionsRDD->ShuffledRDD->MapPartitionsRDD
…
一个算子生成的多个RDD,也不一定归属于同一个stage,例如distinct算子,生成的第一个MapPartitionsRDD归属于前一个stage,其他的则归属于后一个stage,其中产生了一次shuffle。
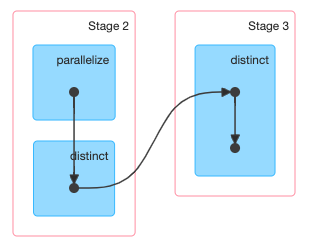
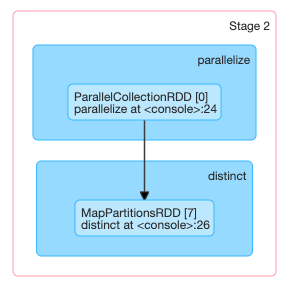
Partition & Partitioner
为什么要把数据分区?
把数据分成若干partition是为了将数据分散到不同节点不同线程,从而能进行分布式的多线程的并行计算。
按什么规则分区?
RDD从数据源生成的时候,数据通常是随机分配到不同的partition或者保持数据源的分区,如sc.parallelize(…),sc.textFile(…)。
这对于某些RDD操作来说是没有问题的,比如filter(),map(),flatMap(),rdd.union(otherRDD),rdd.intersection(otherRDD),
rdd.subtract(otherRDD)。
但是对于reduceByKey(),foldByKey(),combineByKey(),groupByKey(),sortByKey(),cogroup(), join() ,leftOuterJoin(), rightOuterJoin()这些操作,随机分配分区就非常不友好,会带来很多额外的网络传输。影响一个分布式计算系统性能的最大敌人就是网络传输,所以必须尽量最小化网络传输。
为了减少网络传输,怎么分区才合理?
对于reduceByKey操作应该把相同key的数据放到同一分区;
对于sortByKey操作应该把同一范围的数据放到同一分区。
可见不同的操作适合不同的数据分区规则,Spark将划分规则抽象为Partitioner(分区器) ,分区器的核心作用是决定数据应归属的分区,本质就是计算数据对应的分区ID。
在Spark Core中内置了2个Partitioner来支持常用的分区规则(Spark MLlib,Spark SQL中有其他的)。
- HashPartitioner 哈希分区器
- RangePartitioner 范围分区器
HashPartitioner
哈希分区器是默认的分区器,也是使用最广泛的一个,作用是将数据按照key的hash值进行分区。
分区ID计算公式非常简单:key的hash值 % 分区个数 , 如果key为null,则返回0.
也就是将key的hash值(Java中每个对象都有hash code,对象相等则hash code相同),除以分区个数,取余数为分区ID,这样能够保证相同Key的数据被分到同一个分区,但是每个分区的数据量可能会相差很大,出现数据倾斜。
RangePartitioner
RangePartitioner的作用是根据key,将数据按范围大致平均的分到各个分区,只支持能排序的key。
要知道一个key属于哪个分区,需要知道每个分区的边界值。
确定边界值需要对数据进行排序,因为数据量通常较大,通过样本替代总体来估计每个分区的边界值。
采样流程:
- 使用水塘抽样对总体进行采样;
- 针对数据量远超平均值的分区,进行传统抽样(伯努利抽样)。
使用场景:sortByKey
扩展问题:
如何使用
对于一个没有明确指定Partitioner的情况下,
reduceByKey(),foldByKey(),combineByKey(),groupByKey()等操作会默认使用HashPartitioner。
sortByKey操作会采用RangePartitioner。
reduceByKey也有一个可以自定义分区器的版本:reduceByKey(partitioner: Partitioner, func: (V, V) => V)
Function
传入给transformation的函数
transformation会生成新的RDD,传给RDD transformation的函数最终会以成员变量的形式存储在新生成的RDD中。
以map函数为例。
1 | val r11 = r00.map(n => (n, n)) |
map函数接受的参数类型为f: T => U,因为Scala支持函数式编程,函数可以像值一样存储在变量中,也可以作为参数传递。
f参数的类型T => U代表一种函数类型,这个函数的输入参数的类型必须为T,输出类型为U,这里T和U都是泛型,T代表RDD中数据的类型,对于RDD[String]来说,T就是String。
最终f参数,会转换成有关迭代器的一个函数,存储到RDD的f成员变量中。
最终存储的类型为:f: (TaskContext, Int, Iterator[T]) => Iterator[U]
对于map来说是这样一个函数(context, pid, iter) => iter.map(f)
也就是说我们传入到RDD.map的f函数,最终传给了Iterator.map函数。
传入给action的函数
action不会生成新的RDD,而是将函数传递给Job。
Dependency
当RDD1经过transformation生成了RDD2,就称作RDD2依赖RDD1,RDD1是RDD2的父RDD,他们是父子关系。
先看一个例子
1 | val r00 = sc.parallelize(0 to 9) |
我们看下RDD之间的依赖关系图
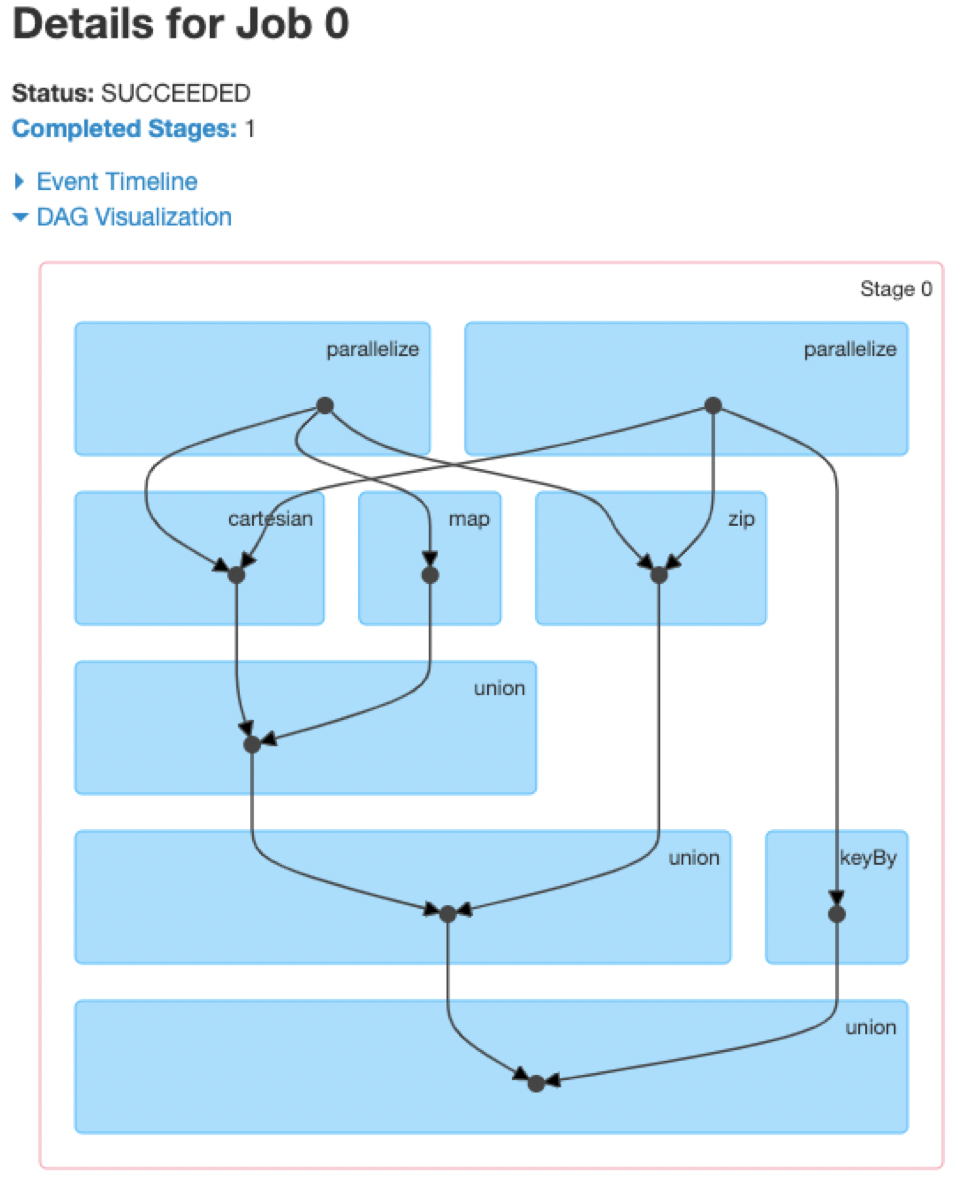
RDD的依赖关系网又叫RDD的血统(lineage),可以看做是RDD的逻辑执行计划。
同义词:RDD lineage,RDD operator graph,RDD dependency graph
Dependency存储
父RDD与子RDD之间的依赖关系记录在子RDD的属性中(deps: Seq[Dependency[_]]),数据类型为Dependency(可以有多个),Dependency中保存了父RDD的引用,这样通过Dependency就能找到父RDD。
Dependency分类
Dependency不仅描述了RDD之间的依赖关系,还进一步描述了不同RDD的partition之间的依赖关系。
依据partition之间依赖关系的不同Dependency分为两大类:
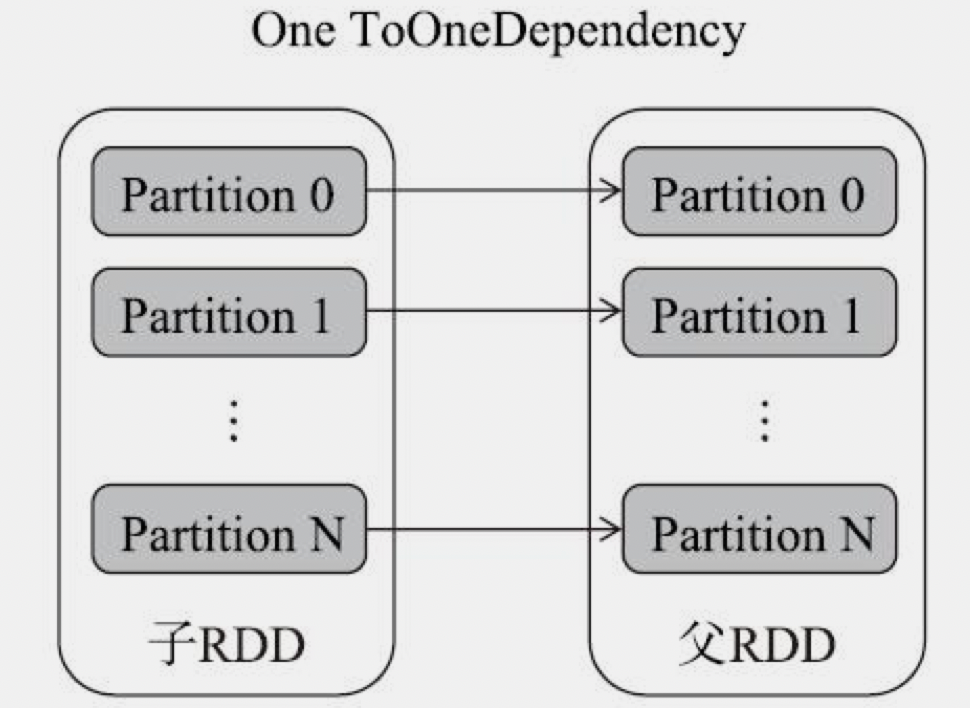
- NarrowDependency 窄依赖,1个父分区只对应1个子分区,这时父RDD不需要改变分区方式。如:map、filter、union,co-paritioned join
- ShuffleDependency Shuffle依赖(宽依赖),1个父分区对应多个子分区,这种情况父RDD必须重新分区,才能符合子RDD的需求。如:groupByKey、reduceByKey、sortByKey,(not co-paritioned)join
NarrowDependency
NarrowDependency是一个抽象类,一共有3中实现类,也就是说有3种NarrowDependency。
- OneToOneDependency:一对一依赖,比如map,
- RangeDependency:范围依赖,如 union
- PruneDependency:裁剪依赖,过滤掉部分分区,如PartitionPruningRDD
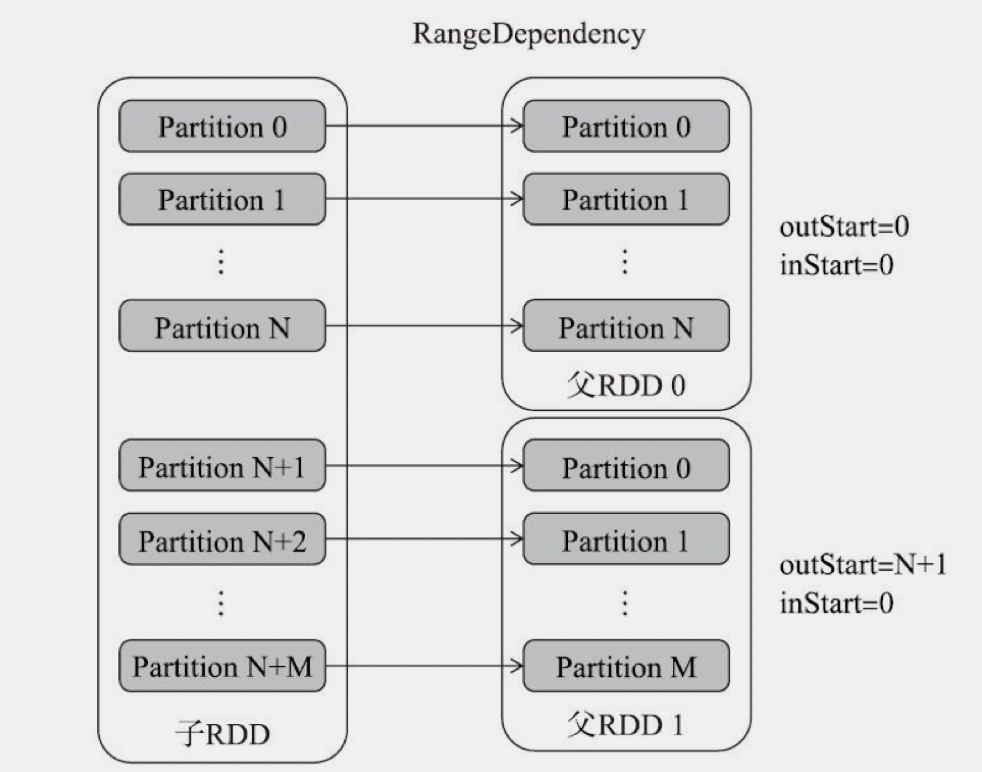
ShuffleDependency
出现shuffle依赖表示父RDD与子RDD的分区方式发生了变化。
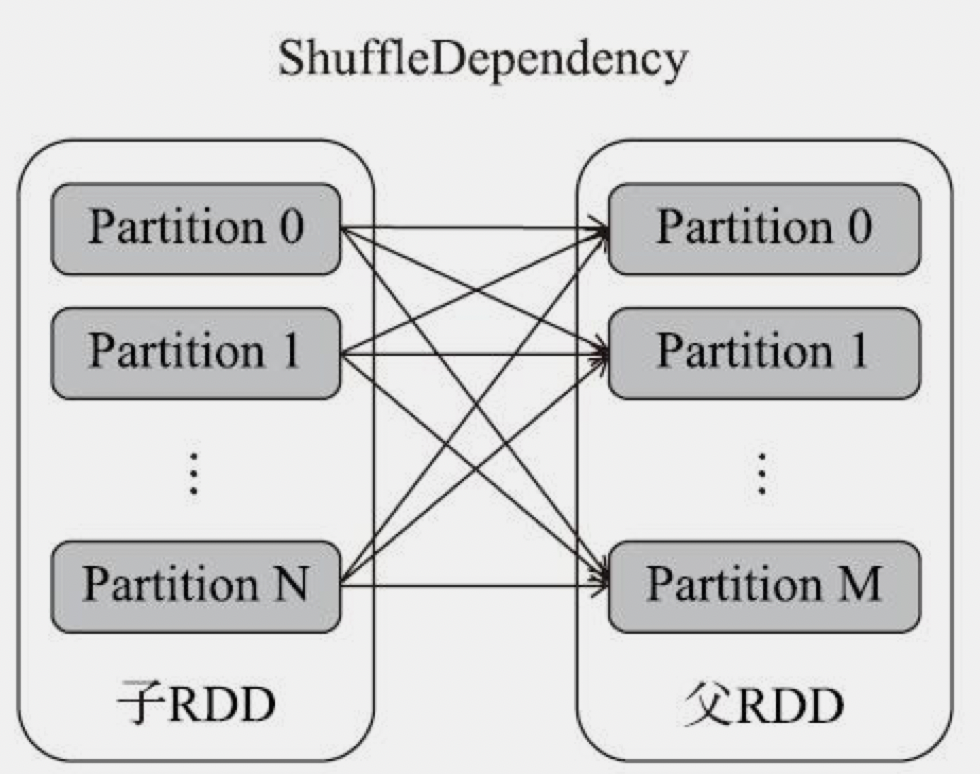
RDD分类
RDD的具体实现类有几十种(大概60+),介绍下最常见的几种。
1 | scala> r20.toDebugString |
不同的RDD代表着不同的‘计算模式’:
MapPartitionsRDD,对Iterator的每个值应用相同的函数;
ShuffledRDD,对Iterator执行combineByKey的模式,可以指定 createCombiner: V => C,mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, compute函数返回ShuffleReader生成的迭代器。
MapPartitionsRDD
MapPartitionsRDD对于父RDD的依赖类型只能是OneToOneDependency,代表将函数应用到每一个分区的计算。
相关transformation:map, flatMap, filter, mapPartitions等等
1 | scala> sc.parallelize(0 to 10000).map(x=>(x%9,1)).dependencies |
ShuffledRDD
对于父RDD的依赖类型只能是ShuffleDependency,代表需要改变分区方式进行shuffle的计算。
会创建ShuffledRDD的transformation:
RDD:coalesce
PairRDDFunctions: reduceByKey, combineByKeyWithClassTag , partitionBy (分区方式不同时) 等
OrderedRDDFunctions: sortByKey, repartitionAndSortWithinPartitions
RDD Checkpoint
Checkpoint检查点,是一种截断RDD依赖链,并把RDD数据持久化到存储系统(通常是HDFS或本地)的过程。
主要作用是截断RDD依赖关系,防止stack overflow(与DAG递归调用有关)。
存储的数据包括RDD计算后的数据和partitioner。
Checkpoint分为两种:
- reliable :调用函数为RDD.checkpoint(),数据保存到可靠存储HDFS,RDD的parent替换为ReliableCheckpointRDD;
- local:调用函数为RDD.localCheckpoint(),数据保存到spark cache中(不是本地),RDD的parent替换为LocalCheckpointRDD。当executor挂掉,数据会丢失。
注意:与streaming中的checkpointing不同,streaming中的checkpointing会同时保存元数据和RDD数据,可以用于Application容错。
如何使用
1 | scala> :paste |
查看HDFS上存储的checkpoint文件
1 | hdfs dfs -ls /tmp/spark-checkpoint/74acd422-2693-4f47-b786-69b4f8dc33ad/rdd-1 |
RDD Cache
Cache机制是Spark提供的一种将数据缓存到内存(或磁盘)的机制,
主要用途是使得中间计算结果可以被重用。

常见的使用场景有如下几种,底层都是调用RDD的cache,这里只讲RDD的cache。
1 | rdd.cache() |
Spark的Cache不仅能将数据缓存到内存,也能使用磁盘,甚至同时使用内存和磁盘,这种缓存的不同存储方式,称作‘StorageLevel(存储级别)’。
可以这样使用:rdd.persist(StorageLevel.MEMORY_ONLY)。
Spark目前支持的存储级别如下:
1 | NONE (default) |
2代表存储份数为2,也就是有个备份存储。SER代表存储序列化后的数据。
DISK_ONLY后面没跟SER,但其实只能是存储序列化后的数据。
要cache RDD,常用到两个函数, cache()和persist(),cache方法本质上是persist(StorageLevel.MEMORY_ONLY),也就是说persist可以指定StorageLevel,而cache不行。
Checkpoint vs Cache
- Cache用于缓存,采用临时保存,Executor挂掉会导致数据丢失,但是数据可以重新计算。
- Checkpoint用于截断依赖链,reliable方式下Executor挂掉不会丢失数据,数据一旦丢失不可恢复。
RDD Broadcast
一种将数据在不同节点间共享的机制,可以将指定的只读数据广播分发到每个Executor,每个Executor有一份完整的备份。
是一种高效的数据共享机制,被广播的数据可以被不同的stage和task共享,而不需要给每个task拷贝一份。
Broadcast机制有个非常重要的作用,Spark就是通过它将task分发给各个Executor。
下面举个使用的例子
rddA
| k | low |
|---|---|
| 1 | a |
| 2 | b |
| 3 | c |
rddB
| k | up |
|---|---|
| 1 | A |
| 2 | B |
| 3 | C |
rddAB
| k | low | up |
|---|---|---|
| 1 | a | A |
| 2 | b | B |
| 3 | c | C |
1 | scala> val rddA=sc.parallelize(List((1,"a"),(2,"b"),(3,"c"))) |
通过broadcast机制,将原本的两个stage计算减少为1个stage。
这里模拟实现了map-side join。
Broadcast VS Cache
Cache也会把数据分发到各个节点,但是一个节点上通常只有部分分区的数据,而Broadcast会保证每个节点都有完整的数据。
Broadcast会消耗更多的内存,但是带来了更好的性能。
RDD Accumulators
Broadcast机制有个短板,它的变量是只读的,于是Spark提供了Accumulators(累加器)来弥补。
Accumulator的值可以增减,但是不能直接修改为指定值。
1 | scala> val acc=sc.longAccumulator |