Spark Core 解析 4:内存模型
Spark内存模型
Spark之所以快,很大程度上是因为它善于利用内存,大量利用内存进行存储和计算,从而减少磁盘IO,提升执行效率。
从1.6版本开始,Spark引入了统一内存管理模型(之前版本只有静态内存管理,这里不细说),找到两张图描述的很清楚:
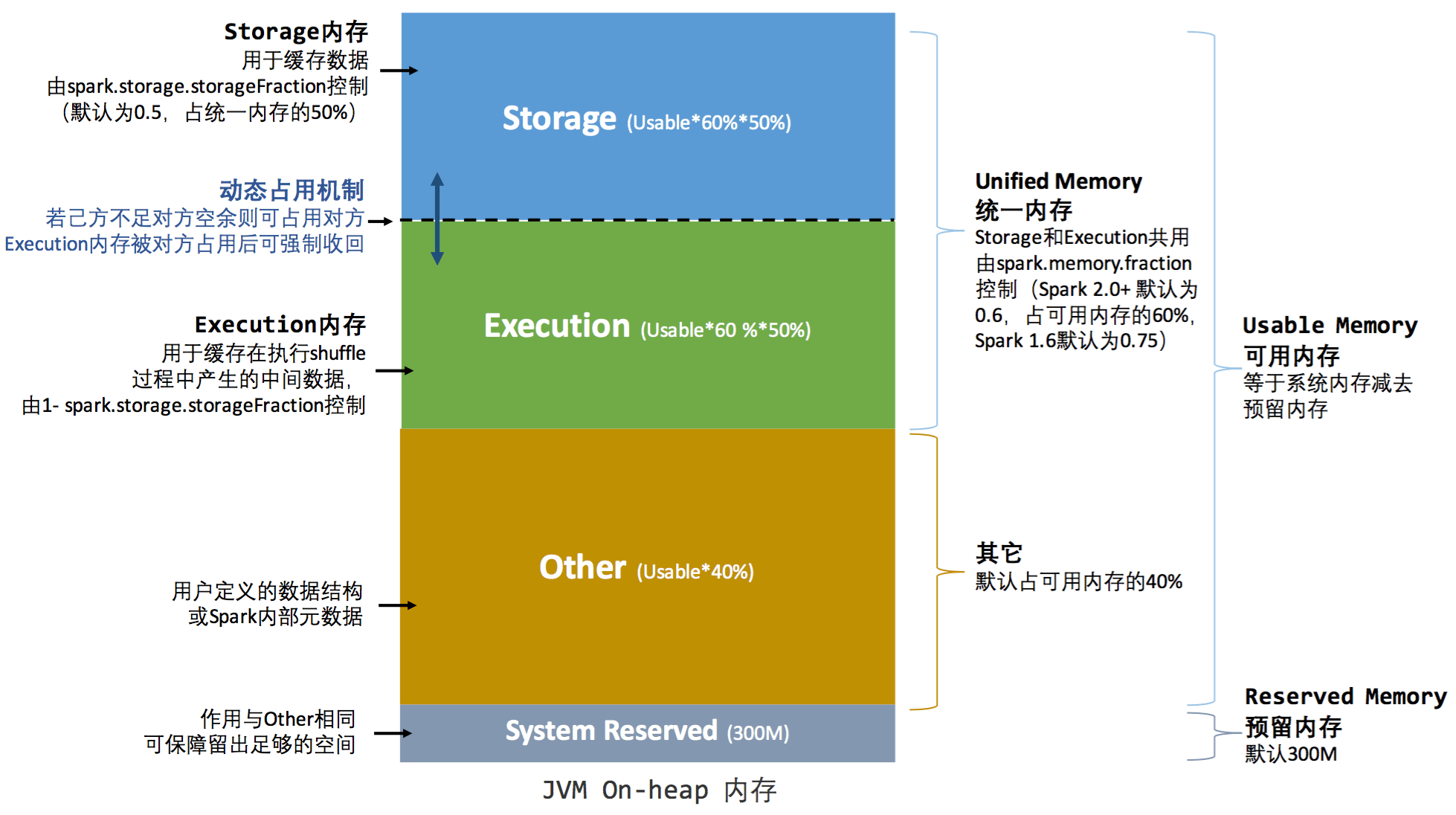
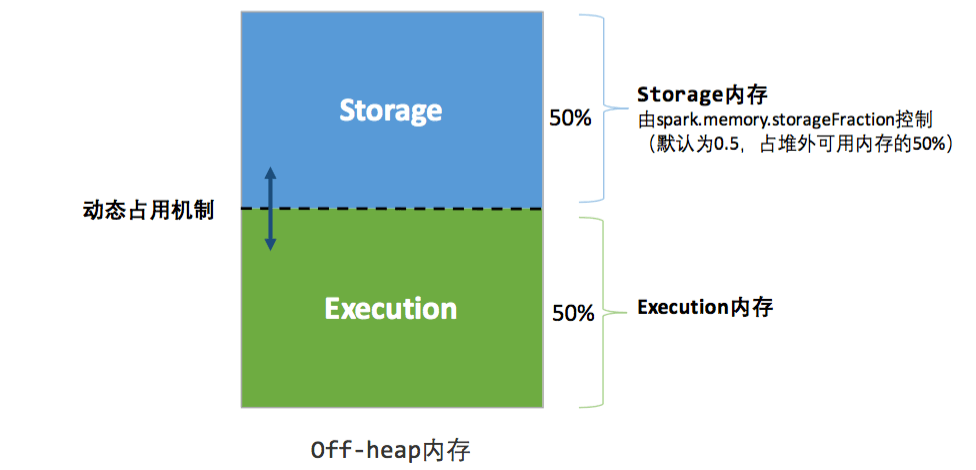
为什么有两张图呢,因为Spark既能使用JVM堆内存(on-heap),也能使用堆外内存(off-heap),两张图分别描述的是这两块内存的情况。图中已经把Spark对内存容量的划分很形象的说明了,网上相关文章也不少,不再赘述。
几个需要注意的点
Storage与Execution区域之间的虚线,代表Storage与Execution内存的容量是可以动态变化的,比如Storage内存不足的时候,可以占用Execution的内存。但是,on-heap中的Storage不可以占用off-heap中的Execution内存,因为on-heap及off-heap整个的大小是固定的,没法互相占用。
Storage与Execution空间都不足时,都需要溢写至磁盘;Execution空间不足时,若有空间被Storage借用,该空间可以通过淘汰或转存磁盘的方式归还;Storage空间不足时,若有空间被Execution借用,则无法立即归还,只能等待用完释放。
Spark对堆内内存的管理是一种逻辑上的”规划式”的管理,因为对象实例占用内存的申请和释放都由JVM完成,Spark只能在申请后和释放前记录这些内存。说白了Spark只是个记账的,记录每次申请了多少内存,就能算出还剩多少内存。然鹅这个内存的帐并不是那么容易精确记录的,往往会对不上帐。首先,对于off-heap堆外内存来说,内存可以比较精确地申请和释放,问题不大。对于on-heap内存来说,序列化的对象可以精确计算大小,但非序列化的对象就只能估算了(出于性能考虑),所以存在记账的内存大小不准的情况。另外,on-heap内存的回收是JVM自动进行的,账本上释放掉的内存空间,不一定已经被回收。因为记账的不准,所以即使进行了内存管理还是会有OOM的风险。
统一内存模型的实现
核心的实现类是UnifiedMemoryManager,其中维护了4个内存账本:
onHeapStorageMemoryPool,offHeapStorageMemoryPool,onHeapExecutionMemoryPool,offHeapExecutionMemoryPool,
分别对应啥一看名字就知道了。
虽然他们叫MemoryPool,还提供了releaseMemory、acquireMemory之类的方法,看上去挺虎,但实际上只是记录已用内存大小,进行数值上的加加减减而已。而Storage与Execution内存的互相借用,其实只是账本MemoryPool大小数值的调整而已。
Execution执行内存
每个Executor有一个MemoryManager,用来管理该Executor节点的内存;
每个TaskAtempt都有一个TaskMemoryManger管理单次Task执行的内存;
每个TaskMemoryManger对当前TaskAtempt中的多个MemoryConsumer进行管理,负责分配内存给MemoryConsumer;
MemoryConsumer就是Spark中最终的执行内存消费者,是一个抽象类,比较典型的实现类有ExternalAppendOnlyMap、ShuffleExternalSorter、ExternalSorter等,不难发现这些类都是与shuffle相关的(还有一些实现类是Spark SQL相关的),也即是说执行内存基本就是shuffle使用的内存。
Shuffle相关可以参考Spark Core 解析 3:Shuffle
Storage存储内存
主要用于存储cache和broadcast的数据,为Spark的存储体系服务。
介绍存储体系的时候再细说。